株式会社ExData では,国立大学法人 東海国立大学機構名古屋大学,特定非営利活動法人 位置情報サービス研究機構と共同で,交通・気象・金融・インフラなど様々な分野から,継続的に収集される時系列データ(以下,実世界データ)を,将来に渡ってサステナブルに利活用するための「実世界データ醸造基盤」の研究開発を推進しています.本研究開発は,国立研究開発法人情報通信研究機構(以下,NICT)による,「高度通信・放送研究開発委託研究課題 データ利活用等のデジタル化の推進による社会課題・地域課題解決のための実証型研究開発」の一環として,2022年12月より実施しています(採択番号:22609).
SemantiPack ベータ版を公開しました!
実世界データ向けの高効率なデータ圧縮ソフトウェア「SemantiPack」のオープンベータ版ウェブサイト「SemantiPack Web」を公開しました.
以下のページより,ブラウザ上で簡単に SemantiPack をお試しいただけます.
https://semantipack.exdata.co.jp/
SemantiPack は,CSV / JSON 形式のデータの意味的構造を利用して,従来手法(gzip)に比べて約 50 % 小さく圧縮します(最良のロスレス圧縮手法と比較しても,平均で約 20 % 小さく圧縮).
さらに,SemantiPack のロスありモードを使用すると,実世界データの特徴をできる限り残しつつ,さらに小さく圧縮できます.
これにより,従来は捨てられていた組織内の実世界データの長期保存と利活用の促進を実現します.
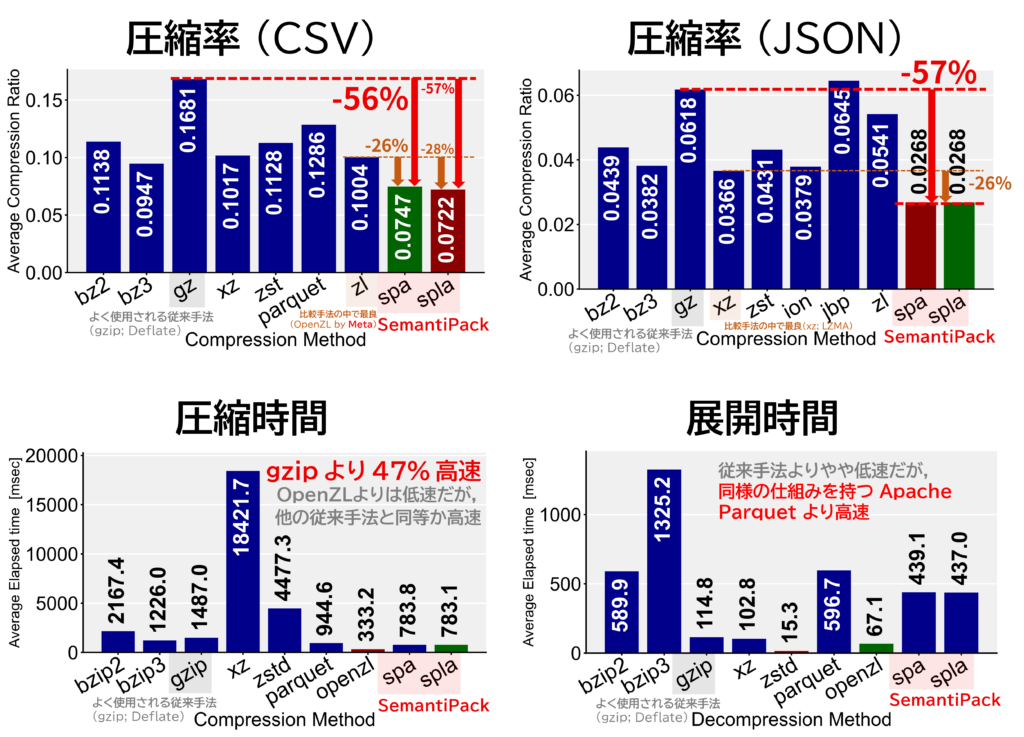
SemantiPack Web では,実際にお手元のデータやサンプルデータを使用して,SemantiPack の圧縮性能をご確認いただけます.
入力されたデータはすべてブラウザ上で処理され,外部に送信されませんのでご安心ください(自動生成された RWD Profile や動作ログは収集する場合があります).
※ SemantiPack Web では,SemantiPack の機能を一部制限した,WebAssembly 版を公開しております.そのため,入力できるデータサイズや処理速度に制限があります.
なお,ExData Account に登録して SemantiPack の無料ベータテスターライセンスを取得すると,入力データサイズの上限が 16MB から 64MB になります.
この機会にぜひご登録いただき,様々な実世界データの圧縮性能をお試しください。
SemantiPack CLI 版ベータテスター応募フォーム
上記でご紹介した SemantiPack のコマンドラインインターフェース(CLI)版のベータテスター様を募集しています. CLI 版は,zip や tar コマンドと同様にご利用いただける上に,より大きなファイルをより高速に処理できます.
大量の実世界データをお持ちで,管理にお困りの方は,以下のフォームに必要事項をご記入の上ご応募ください.ベータテスト期間終了後は,株式会社ExDataより製品版を販売予定ですが,ベータテスト期間中に圧縮したデータは,ベータテスト期間終了後も自由に保管・無料で伸長していただけます.なお,CLI 版ベータテスター様には製品版を割引価格でご提供予定です.
研究開発の背景
IoTセンサやインターネットの普及により,多くの実世界データが収集できるようになり,2010年代後半にはデータ爆発時代が到来したと言われています.特に,コロナウィルス感染症が流行すると,コロナ以前の実世界データとの比較が盛んに行われるようになり,データを継続的に活用する重要性が高くなった.しかし,現状多くの組織では,数年以上の期間で実世界データを使える形で保存されていることは少なく,実際に収集されたデータのうち5%程度しか活用されていないと言われています.ゆえに,将来に渡って実世界データを持続的に利活用する「データ・サステナビリティ」の実現が急務であるといえます.
研究開発の概要
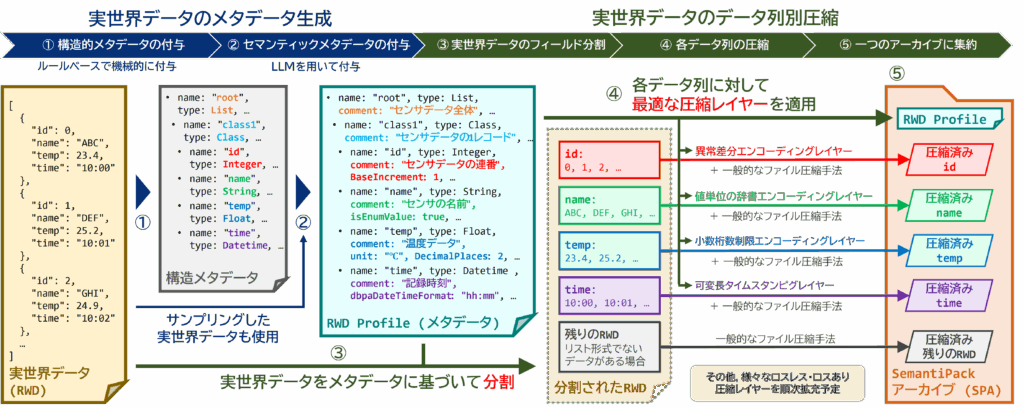
本研究開発では,図1のように官公庁・自治体・民間事業者などの多様な組織が保有する異なる実世界データ収集システムと接続し,質的・時間粒度的・空間粒度的に異なる移動データを収集・仕分け・発酵・濾過・貯蔵・熟成・混合・可視化・分析する「実世界データ醸造基盤」を構築しています.一般に「醸造」とは,発酵作用を利用した酒類や調味料等を製造する過程を指しますが,本研究開発における「データ醸造」とは,実世界データの利活用性を高めるために,分類・圧縮・保存・分析を,時系列的に行う一連の作業を含む過程のメタファです(図2).また,データ醸造の各工程を担うマイクロプログラムを酵母,実世界データから有益な情報を抽出しつつ不必要なデータを削除することを発酵・濾過,実世界データの性質や関係性に基づき,実世界データを可視化・分析で必要とされる形に時々刻々と変換させていくことを熟成と呼びます.さらに,酒類の醸造過程では,異なる種類の酵素・酵母・麹に加え様々なテイストを与えるために副原料を混合させますが,データ醸造においても,必要に応じて適切なデータを混合させ,様々なデータ分析基盤と連携しより多彩な実世界データ活用の可能性を探求します.これにより,従来型のデータ活用では捨てられたり使われず放置されたりした実世界データが,データ醸造によって有効活用できるようになり,データ・サステナビリティを実現します.
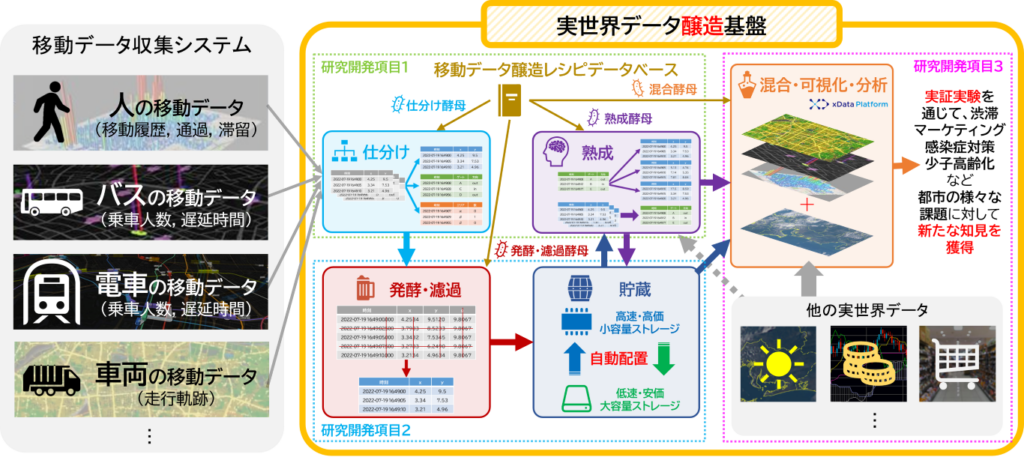
図1. 本研究開発の概要
研究開発の進捗
現在までに,以下の項目について研究開発が進行しています.
- 様々な実世界データに対応したメタデータ表現・管理手法:実世界データに関連する様々なメタデータ(データの収集・生成元や保存先,データ構造,5W1H情報など)を JSON-LD 形式で表現するためのスキーマ定義と,実世界データ醸造基盤でメタデータを管理するためのシステムを開発しています.
- 多様なデータ形式に対応したデータ構造自動解析システム:実世界データのデータ構造(CSV形式の場合はカラム名,JSON形式の場合オブジェクト構造)を,構造解析エンジン及びLLMを用いて自動的に解析し,構造メタデータを生成するシステムを開発しています.
- データ醸造酵母(マイクロプログラム)の基礎設計とサンプル実装:本基盤においてデータ醸造を行う酵母(マイクロプログラム)が満たすべき基本的な仕様と機能表現を行うメタデータの設計を行い,この仕様・設計に準拠したサンプル酵母の実装を行っています.
- 効率的なデータ圧縮アルゴリズムの設計・実装:本基盤に保管する様々な実世界データに適用しうる新たなデータ圧縮形式(DBPA 形式)の設計・実装を行っています.
- データ構造に基づく自動データ可視化システムの設計・実装:実世界データを入力すると,その実世界データから実現可能な可視化(ex. グラフ表示,時空間地点表示,ルート表示,ヒートマップ表示など)を自動的に判断し可視化を行うシステムの設計・実装を行っています.
公開資料・ツールなど
本研究開発では,データ醸造のコンセプトの普及のため,データ醸造基盤におけるメタデータ表現手法や酵母(マイクロプログラム)のサンプル等の資料やツールを公開しています。詳細は、下記の GitHub リポジトリをご覧ください。
https://github.com/exdata-inc/DataBrewingPlatform
対外発表・論文等
- 「実世界データ」高効率圧縮で保管,建設通信新聞 2025.9.16 012面(Web版)
- 膨大すぎる「実世界データ」圧縮で活路 ExData ,建設通信新聞DIGITAL 2025.8.8
- ジオ展2025
- SemantiPack: An Efficient Real-World Data Compressor using Structural and Semantic Metadata(DOI: 10.1109/ACCESS.2025.3583829),Yoshiteru Nagata,IEEE Access,2025.6.27
- 実世界データ醸造基盤の実現に向けて,永田 吉輝,NICT スマート IoT 推進フォーラム技術戦略検討部会 テストベッド分科会 第15回データ分析・可視化タスクフォース,オンライン,2023.11.21
- データ・サステナビリティのための実世界データ醸造基盤,浦野 健太,NICT ICTイノベーションセミナー2023,名古屋イノベーターズガレージ,2023.2.13
お問い合わせ
本研究開発に関するお問い合わせは,弊社お問い合わせフォームにご記入ください。